代码到底怎么写
一个很值得探讨的问题,可惜长久以来也只积累了模糊的感觉。
但是看完A Philosophy of Software Design1之后,可以说是解决了我长久以来的疑惑。
Why
也许会有人说代码能用就行了,干嘛搞那么干净,我又不在这家公司做一辈子。
不过对于我来说,写出优雅和易于维护的代码可以让工作轻松和幸福很多。
一个糟糕的代码库,不仅开发需求困难,连debug都难以下手,时不时就踩个坑。
一个优雅的代码库,新人上手快,需求开发迅速,认知负担小,团队信心充足。
况且破窗效应可以让糟糕的代码库更加拉胯,最后搞一场轰轰烈烈的重构,然后再循环。
从大的角度来看,软件开发是少有的一项不受物理限制的活动,唯一挡在面前的只有我们对系统的理解能力。如果能控制好系统的复杂性,我们就能持续前进。
What
简单来说,系统中所有难以理解和修改的部分都是复杂性。
一个系统模块的复杂性在主观上很好判断,毕竟软件最主要的资产就是代码,而代码是给开发人员看的,好不好维护,基本上很容易有一个初步的判断。而整个系统的复杂性就是由各个模块的复杂性累加起来的。
但是复杂性也和模块的日常维护时长有关系。
比如一个简单的后端API服务,其背后的编译器、操作系统这些部分在通常情况下完全不需要我们操心,所以这部分的复杂性实际上是被很好地隔离掉了,几乎可以不算到系统复杂性中。而业务代码的复杂性是实实在在影响日常维护的,很大程度上组成了整个系统的复杂性。
所以书里也给了一个公式:整个系统的复杂性 = 模块1的复杂性 * 开发人员在这个模块上的工作时长 + ...
How
分层/模块已经是构建软件的基本常识了,但是对于如何组织这些模块,却没有很强的共识。也许你会想到SOLID,但是SOLID的几个原则定义得都比较模糊,在不同的场景下有不同的解读。
而这本书用信息的角度去思考,直达本质。
公理
从信息的角度上来说,每个模块都隐藏了一部分信息 (implementation),也暴露了一部分信息 (interface)。而interface对于上一层的模块来说实际上是认知负担。
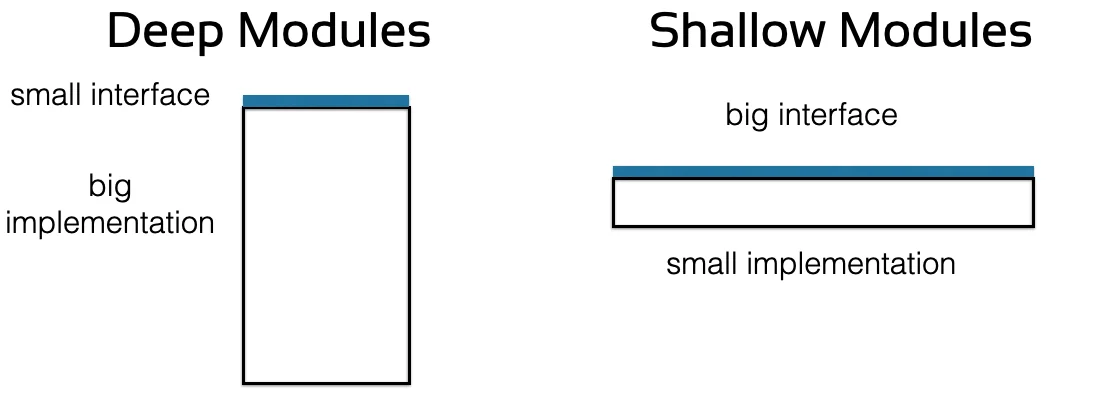
所以在设计模块的时候我们要将interface最小化,把重要的信息提取出来,忽略不重要的细节,也就是图中的Deep Modules。
也可以从成本和收益的角度去理解:一个模块的收益就是其功能,成本就是其interface。
比如Unix I/O的接口设计,简单的接口里隐藏了大量的内部细节,底层实现再怎么迭代,接口几乎没什么变化。
再举一个极端的例子,Go GC机制甚至没有接口,但帮开发人员接管了内存管理,降低了大量复杂性。
定理
基于上面的这个关键公理,我们可以推演出一系列的糟糕实践。
Information Leakage
假设说我们需要改整个网站的背景色,但是却需要在代码里把所有页面的背景色都改一遍,这就是典型的Information Leakage。一个信息反映在了多个模块中,导致了多个模块之间隐式的依赖。一旦这个信息改变,就要影响多个模块。
如果做好了Information Hiding,只需要编辑一处代码就能改整个网站的背景色,不用担心是不是有遗漏。这一点和DRY有异曲同工之处。
如果说一个系统的生命周期里需要不断支持某类固定的需求,比如特征接入、策略上架,那完全可以花时间把这类需求的代码收敛,把需要开发的代码集中到一处,其实就是把Information组织到一处。
Temporal Decomposition
根据代码执行顺序设计模块结构,但是这些模块之间共享一些信息,这些共享的信息实际上是Information Leakage。
应该关注功能所需要的信息去拆分模块,而不是代码的执行顺序。
Pass-through Methods
如果一个函数只是单纯地透传参数,往往说明了这块的设计有点问题。
增加了interface但是没有增加功能,反而创建了一层依赖,也体现了模块的抽象职责不清晰。
Classitis
多类症,认为每个类都要简短。这种误区让开发人员会减少每个类的功能,想要更多的功能就创建更多的类。
实际上太多简短的类堆积了过多的interface,集成困难,而且过多的类也会倾向于给每个类增加冗长的模版代码。
最后
组织代码就是组织信息。用信息的角度去打磨软件,成为高质量产出的工程师吧。
John Ousterhout. 2018. A Philosophy of Software Design. https://book.douban.com/subject/30218046/ ↩︎